Count Duplicates in MySQL (How to Guide)
When working with databases, it’s common to encounter situations where you need to identify and count duplicate records. In MySQL, detecting duplicates can help in data cleansing, auditing, and ensuring data integrity.
Whether you’re managing customer records, sales transactions, or any other dataset, counting duplicates can provide valuable insights. In this article, we’ll explore how to count duplicates in MySQL, including different approaches and practical examples.
Here’s What You Can Do With Five
Create and Model a SQL Database ✅
Write or Build SQL Queries ✅
Visualize Queries as Charts or in Dashboards ✅
Add CRUD Permissions to Control Data Access ✅
Host Your Database Online ✅
“Five bridges the gap between SQL and the web,
allowing me to create full-stack applications almost entirely in SQL”
– Crag Jones, Database Administrator (DBA)
Why Count Duplicates in MySQL?
Counting duplicates is essential for several reasons:
- Data Integrity: Duplicate records can lead to inaccurate reporting and skewed results, making it important to identify and address them.
- Data Cleansing: Removing duplicates helps maintain a clean and reliable database, improving performance and accuracy.
- Business Insights: Understanding how often duplicates occur can reveal patterns and help refine processes, such as data entry or merging records from different sources.
Counting Duplicates with GROUP BY
The most straightforward method to count duplicates in MySQL is by using the GROUP BY clause. This allows you to group records with the same value(s) and count how often they occur. Here’s a basic example:
SELECT column_name, COUNT(*) AS duplicate_count
FROM table_name
GROUP BY column_name
HAVING COUNT(*) > 1;In this query:
column_nameis the column you want to check for duplicates.COUNT(*)counts the number of occurrences for each group of records.- The
HAVING COUNT(*) > 1clause filters out groups that don’t have duplicates (i.e., groups with only one occurrence).
Example:
Suppose you have a table called customers with a column email. To count duplicate emails, you would use the following query:
SELECT email, COUNT(*) AS duplicate_count
FROM customers
GROUP BY email
HAVING COUNT(*) > 1;This query will return a list of email addresses that appear more than once in the customers table, along with the count of how many times they appear.
Counting Duplicates Across Multiple Columns
Sometimes, you may need to check for duplicates based on more than one column. For example, you might want to find duplicate customer records based on both first_name and last_name. In this case, you can modify the query as follows:
SELECT first_name, last_name, COUNT(*) AS duplicate_count
FROM customers
GROUP BY first_name, last_name
HAVING COUNT(*) > 1;This query groups records by both first_name and last_name, counting how many times each combination appears.
Using DISTINCT with COUNT()
In some cases, you may want to count distinct occurrences of duplicates. For example, if you have duplicate records but only want to know how many unique duplicates exist, you can combine DISTINCT with COUNT():
SELECT COUNT(DISTINCT column_name) AS unique_duplicates
FROM table_name
WHERE column_name IN (
SELECT column_name
FROM table_name
GROUP BY column_name
HAVING COUNT(*) > 1
);This query counts the number of unique duplicate values in the specified column.
Removing Duplicates After Counting
Once you’ve identified duplicates, you may want to remove them from your table. MySQL provides several ways to delete duplicates, such as using DELETE with a JOIN or a ROW_NUMBER() function. Here’s a simple example of deleting duplicate rows based on the email column:
DELETE t1
FROM customers t1
INNER JOIN (
SELECT email, MIN(id) AS min_id
FROM customers
GROUP BY email
HAVING COUNT(*) > 1
) t2 ON t1.email = t2.email AND t1.id > t2.min_id;This query deletes duplicate records while keeping the first occurrence of each duplicate based on the id column.
Count Duplicates with a Rapid Database Builder
While understanding the basics of SQL and executing queries isn’t too difficult, building a complete database requires significant SQL knowledge. This is where rapid database builders like Five come into play.
In Five, you can utilise MySQL’s capabilities, including counting duplicates within your data. Five provides a MySQL database for your application and generates an automatic UI, making it easier to interact with your data and detect any duplicates.
With Five, you can create interactive forms, dynamic charts and comprehensive reports that are automatically generated based on your database schema. This means you can efficiently implement and visualize the results of your queries, allowing you to identify and manage duplicate records.
Five also enables you to write custom JavaScript and TypeScript functions, providing additional flexibility to implement complex business logic that may involve detecting and handling duplicates.
This is particularly useful for applications that go beyond standard CRUD (Create, Read, Update, Delete) operations, allowing you to automate and optimize your database interactions.
Once your application is ready, Five simplifies deployment with just a few clicks, allowing you to deploy your MySQL-based application to a secure, scalable cloud infrastructure. This lets you focus on development while Five handles the intricacies of cloud deployment.
If you’re serious about building with MySQL, give Five a try.
▶️ Sign up for free access to Five’s online development environment and start building your web application today.
Now let’s jump back into counting duplicates using MySQL.
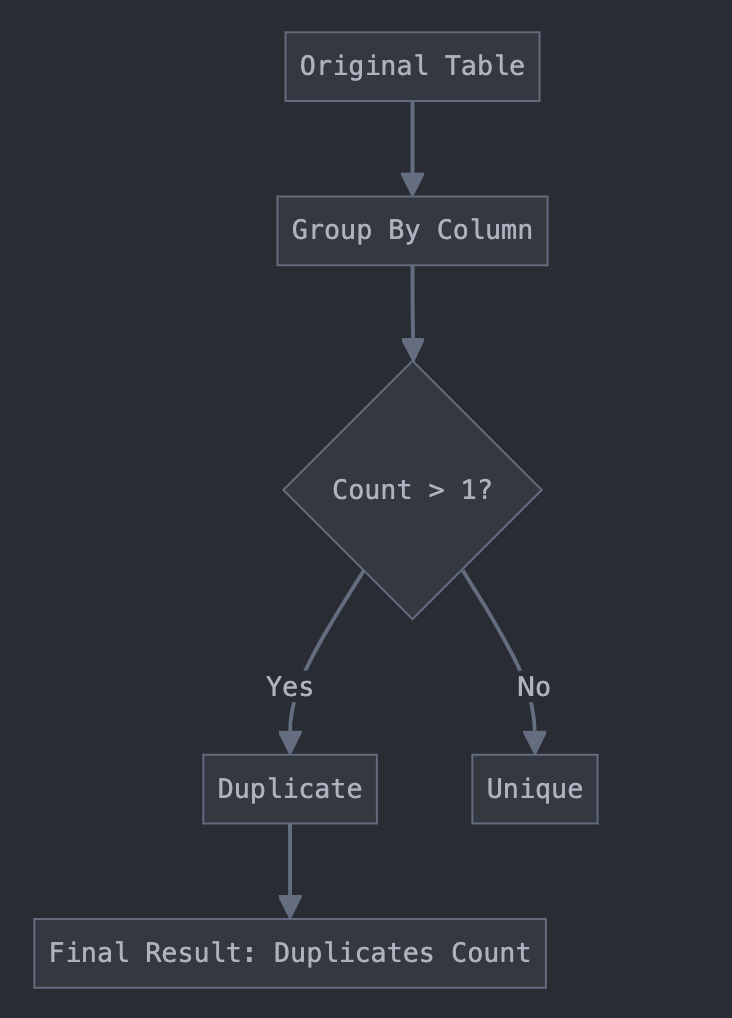
The diagram above illustrates the counting duplicates process in MySQL:
- We start with the original table.
- We group by the column we’re checking for duplicates.
- We count the occurrences of each value.
- We filter for counts greater than 1 to identify duplicates.
- The final result gives us the count of duplicates.
Here’s a sample table to walk you through the process of counting duplicates using MySQL.
-- Create a sample table
CREATE TABLE employees (
id INT AUTO_INCREMENT PRIMARY KEY,
first_name VARCHAR(50),
last_name VARCHAR(50),
department VARCHAR(50)
);
-- Insert sample data
INSERT INTO employees (first_name, last_name, department) VALUES
('John', 'Doe', 'IT'),
('Jane', 'Smith', 'HR'),
('Mike', 'Johnson', 'IT'),
('Sarah', 'Williams', 'Marketing'),
('John', 'Doe', 'Sales'),
('Emily', 'Brown', 'HR'),
('John', 'Doe', 'IT');
-- Count duplicates based on first_name and last_name
SELECT first_name, last_name, COUNT(*) as count
FROM employees
GROUP BY first_name, last_name
HAVING COUNT(*) > 1;
-- Get the total number of duplicate rows
SELECT COUNT(*) as total_duplicates
FROM (
SELECT first_name, last_name
FROM employees
GROUP BY first_name, last_name
HAVING COUNT(*) > 1
) as subquery;
-- Bonus: Get all duplicate records
SELECT e.*
FROM employees e
INNER JOIN (
SELECT first_name, last_name
FROM employees
GROUP BY first_name, last_name
HAVING COUNT(*) > 1
) dup ON e.first_name = dup.first_name AND e.last_name = dup.last_name
ORDER BY e.first_name, e.last_name;Let’s go through this example step by step:
- First, we create a sample
employeestable with some basic information. - We insert sample data, including some deliberate duplicates (three “John Doe” entries).
- To count duplicates based on first_name and last_name:
SELECT first_name, last_name, COUNT(*) as count
FROM employees
GROUP BY first_name, last_name
HAVING COUNT(*) > 1;This query will return:
first_name | last_name | count
-----------+-----------+------
John | Doe | 3- To get the total number of duplicate rows:
SELECT COUNT(*) as total_duplicates
FROM (
SELECT first_name, last_name
FROM employees
GROUP BY first_name, last_name
HAVING COUNT(*) > 1
) as subquery;This query will return:
total_duplicates
-----------------
3- The bonus query shows how to retrieve all the duplicate records:
SELECT e.*
FROM employees e
INNER JOIN (
SELECT first_name, last_name
FROM employees
GROUP BY first_name, last_name
HAVING COUNT(*) > 1
) dup ON e.first_name = dup.first_name AND e.last_name = dup.last_name
ORDER BY e.first_name, e.last_name;This will return all three “John Doe” records with their full details.
This example demonstrates how to identify duplicates, count them, and even retrieve the full records of duplicates if needed. The key is using GROUP BY to identify groups of records and HAVING COUNT(*) > 1 to filter for those groups with more than one record.
Practical Use Cases for Counting Duplicates
- E-commerce Platforms: Detect duplicate customer accounts based on email addresses or phone numbers.
- Sales Databases: Identify duplicate orders that may have been accidentally placed multiple times.
- CRM Systems: Spot duplicate entries in contact lists to prevent redundancy in communications.
Frequently Asked Questions (FAQ)
Q: Can I count duplicates in multiple columns at once?
A: Yes, you can count duplicates across multiple columns by grouping by those columns in your query.
Q: What’s the difference between HAVING COUNT(*) > 1 and using a DISTINCT count?
A: HAVING COUNT(*) > 1 identifies duplicate records, while DISTINCT counts the number of unique duplicates.
Q: Can I count duplicates without displaying them?
A: Yes, you can modify the query to only display the count of duplicates without listing each duplicate record.
Q: How do I handle large datasets with many duplicates?
A: For large datasets, consider indexing the columns you’re checking for duplicates to improve query performance.
Q: Can I use this method to count duplicates in related tables?
A: Yes, you can join related tables and then apply the same counting logic to identify duplicates across those tables.
Summary: Count Duplicates in MySQL
Counting duplicates in MySQL is a valuable skill that helps maintain data integrity and improve database performance. By using the methods outlined in this article, you can easily identify and manage duplicate records in your MySQL database.


